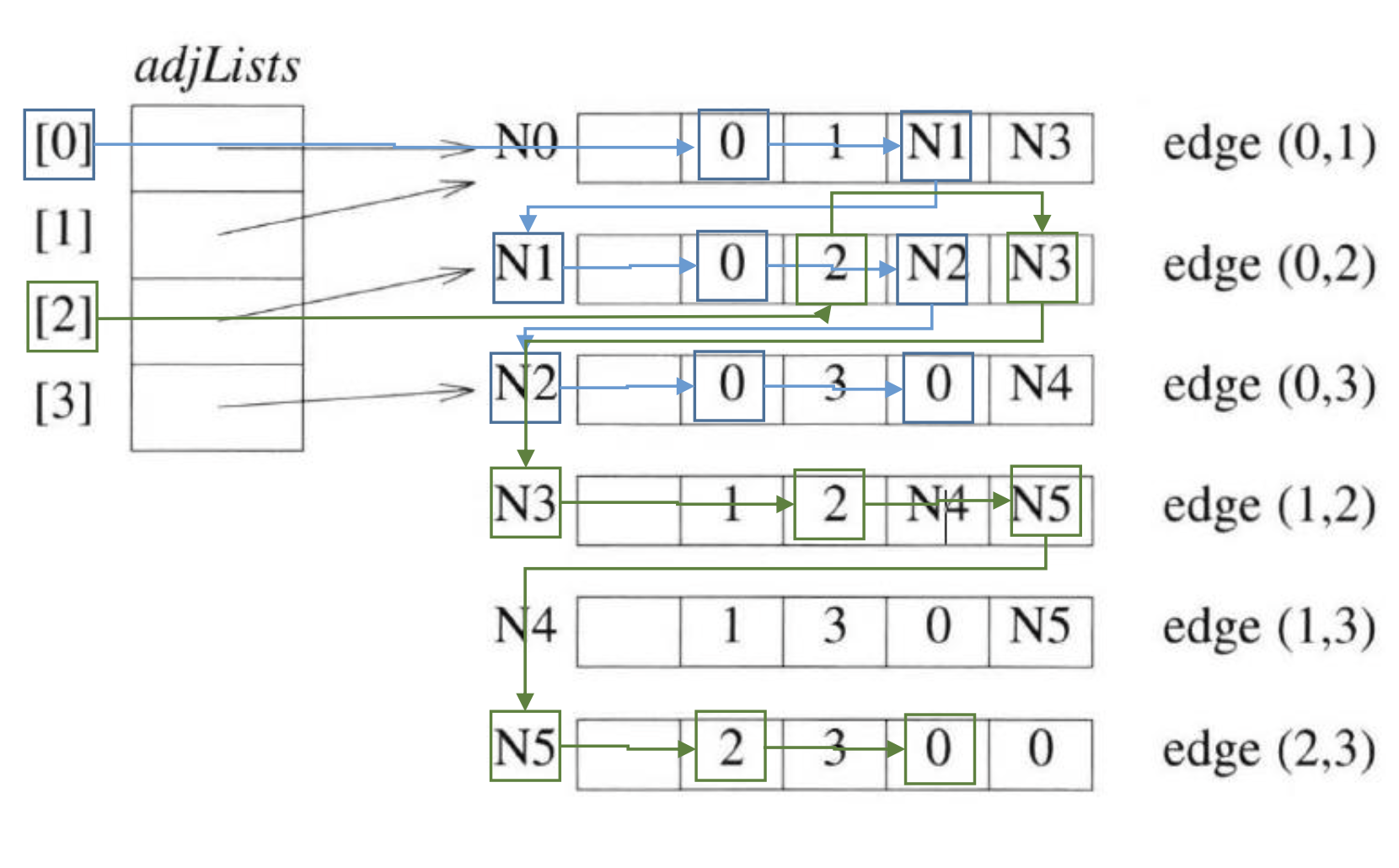
chaining node structure 이의 구성은 각각의 vertex를 설정한 후에 link각각의 vertex에 따른 link 또한 설정한다. bfs, dfs dfs는 preorder 형식으로 VLR 형태로 순환한다. bfs는 levelorder 형식으로 너비우선탐색을 진행한다. 스패닝 트리 minimum cost spanning tree은 세가지 algoritm에 사용된다. - Kurscal's algoritm 가중치가 작은 간선중에 사이클이 만들어지지 않을 때에만 연결한다. - Prim's algoritm 루트 노드 부터 시작해서 가중치가 작은 노드만을 연결해서 나간다. disjoint union 분리 집합 트리들을 합칠 때에 있어서 부모 노드 끼리 연결을 함으로서 합쳐주는 방식이다. aoe,a..