프로세서란 cpu의 한 부분으로 명령을 해석하는 부분이다.
우선 프로세서의 성능을 알아보자.
프로세서의 성능은 CPU Time으로 알아볼 수 있는데, CPU Time = CPU Clocks Cycles * Clock Cycle Time 이다.
이때에 Clock cycle Time 은 Clock rate의 역수와 같다. 따라서 CPU Time = CPU Clocks Cycles / Clock rate 와 같다.
clock rate = Clock Cycles / seconds
또한 이때의 CPU Clock Cycles = Instruction Count * Cycles Count Per Instruction 과 같다.
이때 줄여서 IC * CPI 로 나타낸다.
따라서 CPI = Clock Cycles / Instruction Counts 와 같다.
이때, CPI 는 다른 말로 한다면 instruction 당 clock Cycle의 수라고 할 수 있다.
이제, CPU Time = (Instructions / Program) * (Clock Cycles / Instruction) * (Seconds / Clock Cycle)
로 작성할 수 있다.
따라서 CPU Time 을 개선하기 위해서는 CPI 를 줄이거나 Clock rate 를 높여야 한다.
이때에, CPI 는 Clock Cycles / Instruction Counts 이므로 이것이 파이프라인을 구현하지 않고 single 로 instruction 이 처리 된다고 한다면, instruction 하나당 cycle 이 하나가 들기 떄문에 1이다.
이때 파이프라인으로 나눈다면, 파이프라인의 수를 p라고 하고, instruction의 수를 n이라고 한다면, cpi = p + ( n -1) / n 이다.
이때 n 이 무한히 커진다면 1에 수렴하게 된다.
따라서 파이프라인을 구현하지 않은 processor 와 CPI 가 동일하다. 하지만, 파이프라인을 구현한 경우에는 clock rate가 커지므로 결과적으로 cpu 가 빨라지게 된다.
이러한 파이프라인을 구현하는 방법은 앞에서 다루었고, 이제 파이프라인에서의 문제점을 알아보자.
파이프라인에서의 문제점을 hazard라고 하는데, 이때에 나타나는 hazard는 크개 세가지이다.
구조적 해저드, 데이터 해저드, 컨트롤 해저드가 존재한다.
구조적 해저드는 파이프라인을 나눈 후에 각각의 부분마다 다른 기능을 수행하게 되는데에 이때에 구조적으로 수행이 불가능한 경우를 구조적 해저드라고 한다.
따라서 이는 instruction을 저장하는 memory와 데이터 저장 memory를 나누면서 해결이 되었다.

다음으로는 데이터 해저드가 있다. 이는 instruction들 사이에서 의존성이 발생 할 때에, 발생하는 오류이다.
예를 들어서
add $s0, $t0, $t1
sub $t2, $s0, $t3
이라고 한다면, $s0에 대해서 의존성이 발생한다.
따라서 이를 해결하는 가장 간단한 방법은 명령 실행을 미루는 것이다. 이를 그림과 같이 나타낸다면 아래와 같다.

다른 방법으로는 fowarding 이라는 방법이 있다. 이는 연산이 계산되는 단계는 ex이고, 연산된 결과가 저장되기 전까지는 mem, wb단계가 남아있는데, 이때의 아직 저장되지 않은 결과 값을 가져오는 것이다.
id 단계에서 읽을 때에도 의존성이 발생하지 않는냐고 생각할 수 도 있지만, 이는 wb를 조금 더 빨리 실행시키는 방안으로 해결할 수 있다.
fowarding 회로를 그림으로 나타낸다면,

위와 같이 나타낼 수 있다.
하지만, 이를 통해 해결되는 경우는 산술일때의 의존성만을 해결한다.
해결되지 않는 경우는 load use data일때는 해결되지 않는다.
예를 들어
lw $2, 20($1)
and $4 $2 $5 인 경우에 발생한다. 이 경우에는 mem 단계에서 lw 가 값을 가져오게 되는데, 이를 통해 계산을 한다면, 이때에는 stall 이 반드시 일어날 수 밖에 없다.

따라서 이때에 일어나는 stall을 피하는 방법은 instruction의 순서를 바꾸는 방법 밖에는 없다.
이는 보통 컴파일러 에서 스케줄링을 해주게 된다.
lw의 데이터 해저드에서 일어나는 stall의 경우는 아래의 그림과 같이 detection을 통해서 다음에 넘어가는 control signal 부분만을 nop으로 만들고 같은 주소 값을 다시 한번 fetch 하도록 한다.

따라서 아래와 같은 사이클을 가지게 된다.

데이터 해저드를 정리하자면, resource의 의존성이 있을때에 발생하고, 산술명령의 의존성은 뒤의 두개의 명령어 까지 영향을 미치고,
lw의 의존성의 경우에는 뒤에 하나의 명령어 까지 영향을 미치는데, 이때에 lw 뒤의 의존성은 반드시 stall 을 해야만 한다.
하지만, stall 이 많을 수록 성능이 저하되므로 stall을 피하기 위해서는 스캐줄링을 하는 방법밖에 없다.
control hazard는 branch hazard 라고도 한다.
초기에 branch를 한다면 mem 부분에서 branch 여부를 판단하고 branch 주소를 넘겨서 최종 branch를 하였다.
따라서 그때동안 읽힌 명령어들은 버려지게 된다.

따라서 이를 해결하기 위해서 branch 주소 계산하는 부분과 branch 판단하는 부분을 레지스터를 읽는 부분으로 옮겼다.
그리고 이에 따라서 만약에 lw 뒤에 바로 branch 가 온다면 필여적으로 두번 쉴 수 밖에 없다.

하지만, 이렇게하더라도 brach 를 하게 된다면, stall을 피할 수 없다. 따라서 이를 피하기 위해서 예측을 도입하게 된다.
예측은 branch 를 할지 말지를 예측을 하게 된다. 그래서 예측에 따른 다음 주소값을 대기 시킨 후에 만약에 예측이 틀린다면 flush 를 통해 instruction을 nop으로 바꾼후에 올바른 주소값을 넘겨준다.
이때의 flush는 instruction부분 만을 0으로 초기화 시킨다.
예측을 할때에는 2bit 버퍼를 이용하게 되는데, 그 이유는 예측이 틀릴때마다 브랜치 예측을 바꾸게 된다면 stall 이 자주 발생하기 때문이다.
예를 들어 이중 for 문을 순회 한다고 하였을 때에 예측이 틀릴 때마다 예측을 바꾸게 된다면, 안에 있는 for를 처음돌때, 빠져 나올때, 밖의 for를 돌때, 나올때 이렇게 stall 이 발생한다 하지만 2bit 를 이용한다면 안의 for 를 순회 하면서 2번 stall 발생후 안의 for 탈출, 밖의 for 탈출 일때에만 발생한다. 이때에 같아 보일 수 있지만 1bit경우 밖의 for 문을 돌 수록 stall 이 계속 2번씩 발생한다 그 이유는 탈출한 후에 바로 다시 돌기 때문이다. 하지만 2bit의 경우에는 1번 뿐이 발생하지 않는다.
따라서 2bit buffer 를 통해 예측을 한다면 stall 을 줄일 수 있다.
따라서 위와 같이 예측을 한다면, branch hazard 를 해결 할 수 있다. 하지만 예측이 틀릴 시에는 stall 을 한번 발생시키고 올바른 주소를 fetch 하게 된다.
오류와 예외처리
명령어를 실행하다 보면 오류 또는 예외가 발생하게 된다. 이때의 회로에서의 대처 방법을 알아보자.
명령어에서의 오류는 주로 연산을 할때에 발생하게 된다.
오류의 종류로는 오버플로우가 있다.
우선, 예외가 발생하게 되면 예외가 발생한 pc 값을 EPC 에 저장을 하고 그 원인을 cause reguster에 저장을 하게 된다. 그리고 특정 주소의 운영체제로 제어를 옮기게 된다. 이떄의 특정 주소는 생성된 오류의 종류에 따라서 예외 벡터의 주소가 정의 되어있는데, 이를 따라서 오류처리 주소로 연결된다. 그리고 오류가 발생한 명령어 이후의 명령어들은 flush를 시킨다.
그런데 이때에는 명령어들을 0으로 만드는 것이 아닌, control signal을 0으로 만들어 준다. 그리고 오류처리를 실행 시킨다.
그리고 다시 시작하기 위해서는 EPC에 저장된 주소값을 사용하면 되는데, 이때에 EPC에 저장된 주소는 오류가 발생한 주소보다 4 큰값이므로 4를 뺴서 사용해야 한다.

위의 그림처럼 예외가 발생한다면, 연산 단계에서 오류가 발생하고, 해당 주소 + 4의 값이 EPC에 저장이되고, EX, ID, IF flush 가 실행되어서 그다음 그림은 아래와 같다.

3군데가 flush 되어서 넘어가게 되고, 오류처리를 위해 80000180이 fetch 가 된다.
예외가 많이 발생하게 된다면, 먼저 발생한 예외를 먼저 처리해 준다. 예리한 예외처리는 힘들다!
지금까지 설명한 pipeline 기법은 성능 측면에 있어서 clock rate를 높이기 위한 노력이었다. 여기서 다시 한번 설명하자면 clock rate는 1초에 실행되는 cycle의 수이다. 따라서 cycle의 크기가 줄어든다면 1초에 더 많이 실행 할 수 있고, clock rate가 높아져서 결국 cpu time이 빨라지게 된다.
(cpu time = CPI * IC * cycle time) cycle time은 clock rate의 역수이다. clock rate는 1초에 cycle이 얼마나 실행 되는지.. cycle time은 cycle 하나의 실행시간 이기 때문이다.
이제 IC는 줄일수 없기 때문에, CPI 를 줄이는 방법을 알아보자. 우선 CPI 는 cycles per instruction으로 한국말로는 명령어당 싸이클의 개수, 수식으로는 Cycles cnt / instruction cnt 이다.
따라서 이를 줄이려면 IC는 거의 고정이므로 Cycle Cnt를 줄여야하는데, 싱글과 파이프라인에서의 stall 없는 이상 적인 값은 CPI 가 1이다. 이보다 줄어들려면 cycle 하나당 여러개의 명령어가 실행이 되어야한다. 그렇게 되면 ,한번에 두개씩 실행된다고 하였을 때에,
(p + (n / 2 )) / n 이 된다. 따라서 n 이 무한대로 간다면 1 / 2 이 된다. 이를 역수로 뒤집어서 IPC 라고 부르기도 한다.
이를 multiple issue 라고 하는데, 이런 mutiple issue 와 파이프라인의 특징은 명령어 수행에서의 병렬성을 띈다는 것이다.
따라서 이를 ILP, instruction level parallelism, 명령어 수준의 병렬이라고 한다. 따라서 반대로 ILP를 높이기 위해서는 파이프라이닝을 깊게 하는 방법과, 많은 multiple issue를 수행하는 방안이 있는 것이다.
이제 multiple issue, 다중내보내기에 대해서 알아보자.
다중내보내기에는 정적 다중내보내기와, 동적 다중내보내기가 있다. 정적인 경우에는 컴파일러가 스케줄링을 통해서 명령어들을 packet으로 묶어서 내보내는 방식이다.
동적 내보내기인 경우에는 회로 자체에서 동적으로 다중으로 실행을 시키는 것이다.
따라서 정적인 경우는 소프트웨어 단계, 동적인 경우는 하드웨어적인 단계라고 할 수 있다.
먼저 정적 내보내기의 경우에서 명렬어들의 packet을 VLIW(very long instruction word) 라고도 한다.
그리고 명령어를 다중으로 내보낵 위해서는 서로 기능이 겹치면 안된다. 왜냐하면 한번에 실행이 되어야 하기 때문이다. 그리고, 동시에 실행되는 명령어 사이에 의존성 또한 존재해서는 안된다.
따라서 회로를 나타내면 아래와 같고, 주로 연산 명령어 들과 lw/ sw 저장 ,적재 명령어들을 묶게 된다.

그리고 이렇게 실행할 경우에 스케줄링이 더욱 중요해지는데, 그 이유는 load word hazard의 경우에는 stall 이 무조건 한번 발생하게 되는데, single 일 경우에는 손실이 한 싸이클이지만, 이는 multiple issue이기 때문에, stall이 배가 된다.
이제 이러한 스케줄링에 대해서 알아보자.

위와 같이 스케줄링을 진행하는데, 의존성을 최대한 줄인 후에 ALU / Branch 와 LW / SW를 묶어주게 된다.
이떄의 IPC는 5 / 4 로 1보다 크다. 이때의 이상적인 IPC는 nop이 없는 경우, 2 이다.
따라서 이러한 반복문의 경우에 nop을 채우기 위해서 반복문을 펼치기도 한다. 이를 unrolling 이라고 한다.

위와 같이 unrolling을 한다면, 명령어들이 많아지지만, 위의 표의 nop을 매울 수 있고, 결과적으로 IPC가 2에 가까워지게되면서 성능은 더욱 좋아진다.
중간에 register renaming 같은 경우는 굳이 같지 않아도 되는 부분은 다른 레지스터를 할당하므로서 의존성이 없음을 나타낸다.

따라서 최종으로 위와 같이 되어 명령어 수는 많아졌지만, 결국은 더 빨라지게 된다.
이제 동적 다중 내보내기에 대해서 알아보자. 이러한 동작을 하는 프로세서는 superscalar 라고 한다.
이는 컴파일러에서 스케줄링을 받지 않고 진행하는데, 코드의 의미는 cpu에 의해서 보장된다.
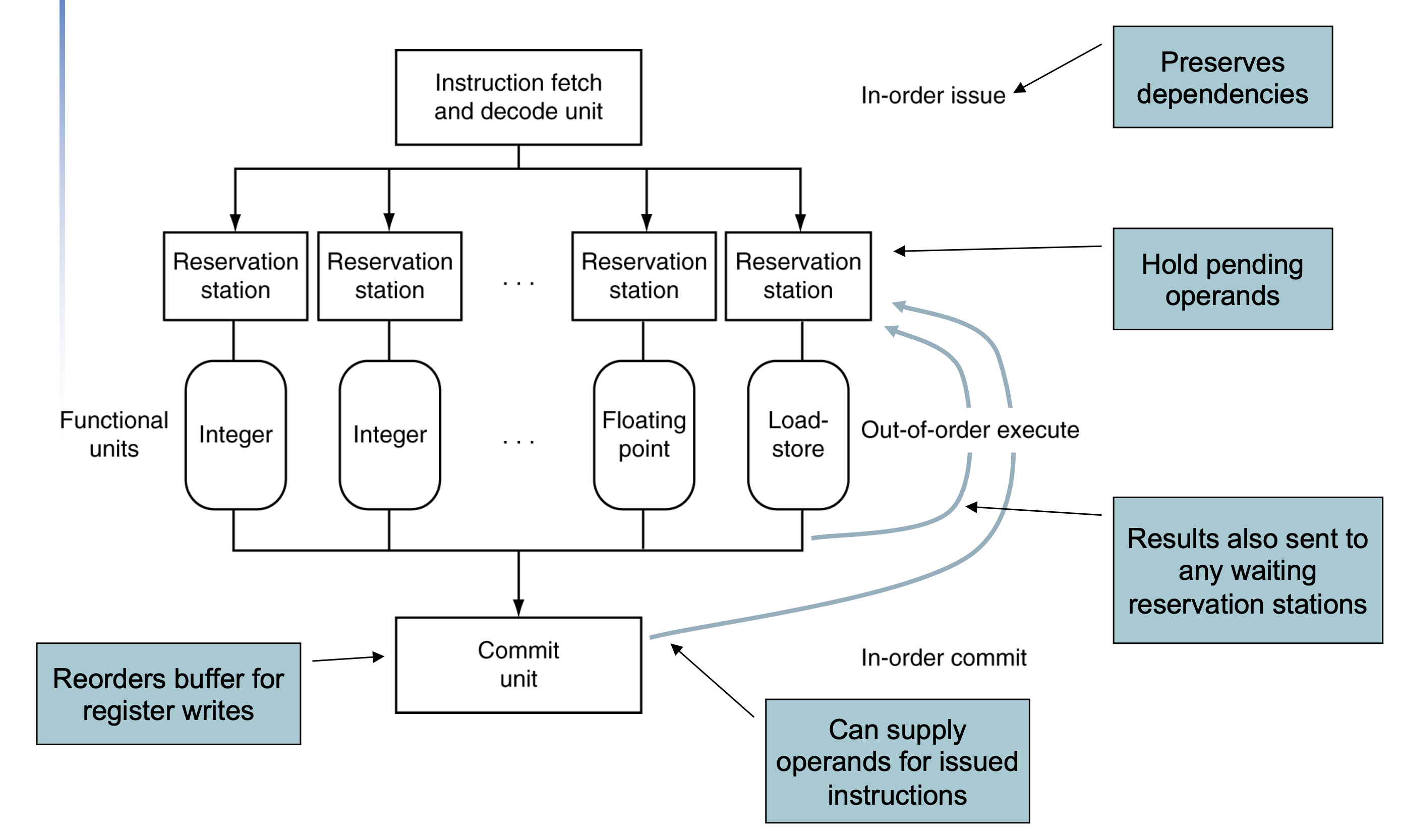
프로세서는 위와 같이 구성되는데, 동작 순서는 우선 instruction이 순서 대로 들어간다.
그리고 피연사자들이 준비 될 때까지 대기를 하다가 준비가 완료되면 실행을 하고 commit unit 에 쌓여 차례대로register에 기록된다.
따라서 commit 과 input의 경우는 in-order로 실행되어서 code의 semantic을 보장해준다.
하지만 실행에 있어서는 병렬적으로 실행된다.
그리고 이때에도 예측을 하게 되는데, 이를 speculation이라고 한다. 이 예측에는 앞서 다루었던 brach prediction 또한 포함된다.
이렇게 multi issue 와 파이프라이닝 들은 트랜지스터의 집적도가 높아짐(무어의 법칙)에 따라서 구현이 가능하지만 이런 병렬성을 많이 이용하게 되면 속도는 빨라지게 되지만 전력량이 증가하게 된다.

이때의 frequency는 클럭 속도이고, capacitive load는 트랜지스터의 개수에 따라 증가하게 된다. 따라서 병렬성이 증가하면 capacity load 가 증가 하게 된다. 따라서 사람들은 프로세서의 병렬성을 조금 낮추고 단일 프로세서가 아닌 다중 프로세서로 CPU를 구성하였다.
이렇게 멀티코어로 넘어옴에 따라서 개발자들이 코드가 이를 잘 활용하도록 작성의 필요성이 증가 되었다.
이렇게 컴퓨터를 발전시켰는데, 이제 컴퓨터의 성능을 비교해보자.
성능을 비교하기 위해서 만들어진 것은 SPEC라는 프로그램이다. 이를 활용하는 방법은 SPEC를 실행시켜서 specRatio를 비교한다 . 이값이 클수록 성능이 좋은 컴퓨터다. 따라서 실행시간은 SpecRatio의 역수라고 할 수 있다.

specRatio의 평균을 구하기 위해서는 기하평균을 활용한다.

이때의 전력량 또한 나타내는데, 아래의 표와 같이 나타낸다.

성능 시간 개선에 대한 식 또한 있는데, 이때에 사용되는 식을 amdhal의 법칙이라고 하는데, 아래와 같다.

이 식의 의미는 개선 시간은 영향을 주는 요인을 얼마나 줄이냐에 달려 있다는 것이다.
명령어 실핼 속도 또한 있는데,이를 mips(millinon instruction per second) 라고 한다. 아래와 같다.

'컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터 구조 execute 과정 & delay (0) | 2022.10.13 |
|---|---|
| 컴퓨터 구조 (0) | 2022.10.11 |
| 컴퓨터 구조 (1) | 2022.10.04 |
| 컴구 translation and startup (1) | 2022.09.30 |
| 컴퓨터 구조 (07) (0) | 2022.09.29 |